If Not Code, What Are You Reading?
My cofounder asked me this a few weeks ago and I haven’t stopped thinking about it. We were talking about background agents, and he asked:
“If you don’t plan on reading the code, what do you plan on reading?”
Not afterward. Right now, as you’re doing the work. What are you looking at?
I bet it’s your prompt. Your prompt is your plan — what you’re trying to do, how, what to watch out for. You iterate on it, you add context, you fix the thing that broke last time.
But you don’t have a feedback loop. You have a prompt going in and code coming out, and very little in between. When it works, the AI generates more code than you can meaningfully review. When it doesn’t, it generates far more code than you can review, and none of it passes the smell test. Either way, the AI is doing stuff you can’t see, can’t interact with, can’t steer.
This is why AI coding feels knife-edge. Not because the models are bad. Because the only thing you can read is your own prompt, and your prompt is doing way too much.
Your prompt is doing four jobs
Any project, from a small feature to a full rewrite into Rust, has four parts someone needs to keep track of.
The goal. What does success look like? It’s stable. It barely changes.
The approach. How to do it, and what not to do. The blessed patterns, the context the LLM doesn’t have, the “last time you tried X it failed but you don’t remember that.” This is the part you iterate on.
The inventory. What needs the work. How many files, which ones, what shape they’re in. This is a spreadsheet. It does not fit in a paragraph.
The state. Where are we. What’s been tried, what passed, what failed, what changed. This evaporates between sessions.
The goal and the approach are prompt-shaped. Text, instructions — a prompt handles them fine. The inventory and the state are not. They’re data that changes constantly, and you need to be able to filter them, slice them, browse them. But most teams have all four jammed into one place, which means you can’t look at the shape of the work and ask the most important question: is this even the right problem?
The inventory is a reality check
Enzyme → RTL. Easy to say “rewrite all the tests.” But look at the inventory and you see that rewriting most of those tests is garbage: they test behaviors you can’t replicate in RTL, because RTL doesn’t work that way. The right move for half of them is deletion, not migration. You’d never know that from the prompt.
“Delete inactive users.” Sounds like a feature. But look at what the codebase actually has: user_id is a nullable field that’s practically assumed to be filled everywhere. Ownership is threaded through six services. The inventory tells you this isn’t a feature. It’s a rearchitecture. If it takes that much work, you’ve probably framed the problem wrong.
This isn’t “should the product have this feature.” It’s “given what this actually involves, is this the right solution?”
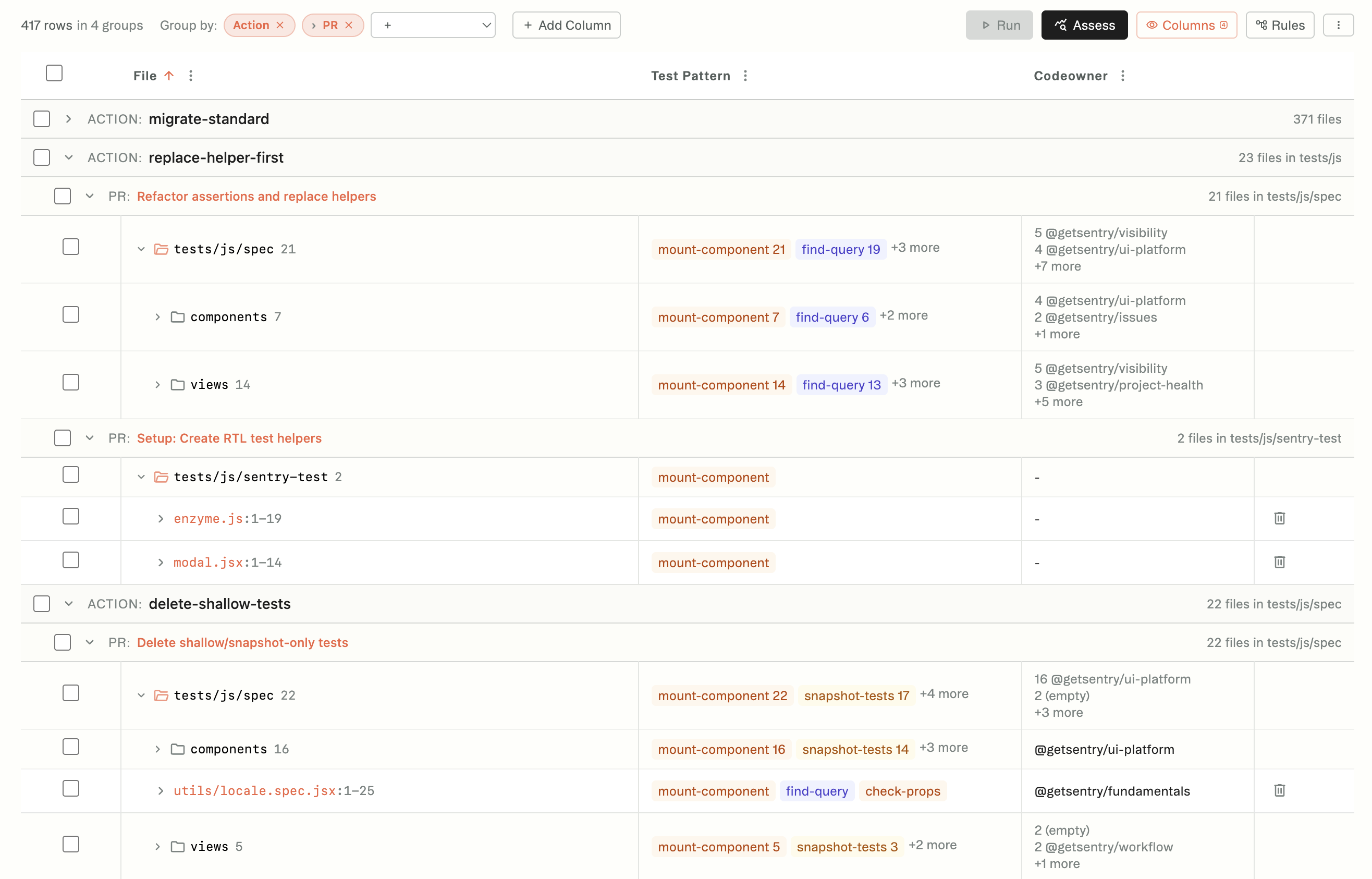
The inventory gives you a lever that isn’t “review these 10,000 lines.” You can see the shape of the work before the code gets written. You can decide how much steering the project needs—full delegation, light oversight, hands-on iteration—before you commit.
State tracking comes later, as you iterate. Every time you run the approach against the inventory, results come back: what passed, what failed, what changed.
That’s your feedback loop.
What humans read
Back to my cofounder’s question.
If you don’t plan on reading the code, what do you plan on reading? The inventory and the state. The prompt, as it runs on a few of them.
That’s what we’ve been building at Tern. A spreadsheet glued to a prompt library. A place to iterate and scale your prompts. Our background agents read your codebase and show you what a change actually involves, so you can decide how to proceed before you commit to 10,000 lines of AI-generated code.
What are your agents going to produce that your team can actually read?